若对树与二叉树的相关概念,不太熟悉的同学,可移置上一期博客
链接:二叉树第一期:树与二叉树的概念-CSDN博客
本博客目标:对二叉树的顺序结构,进行深入且具体的讲解,同时学习二叉树顺序结构的应用——数据结构:堆的实现,以及堆的应用:如堆排序,又或者TOP-K问题;
感谢移置残风的主页:残风也想永存-CSDN博客,❤❤❤
一、堆的定义
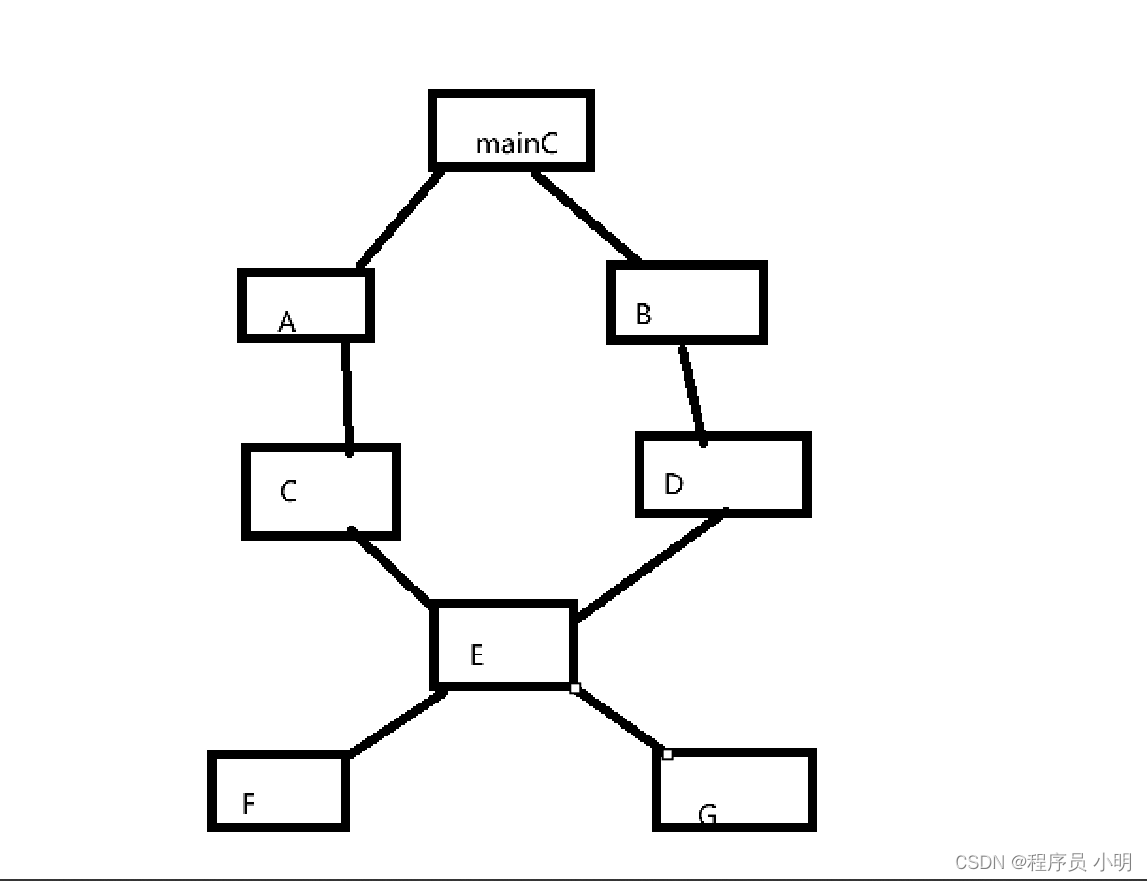
- 堆的定义:堆是一颗完全二叉树,且所有的父亲结点与子结点有相同的大小关系。
- 大堆:所有的父亲结点的值 都比 子结点要大。
- 小堆:所有的父亲结点的值 都比 子结点要小。
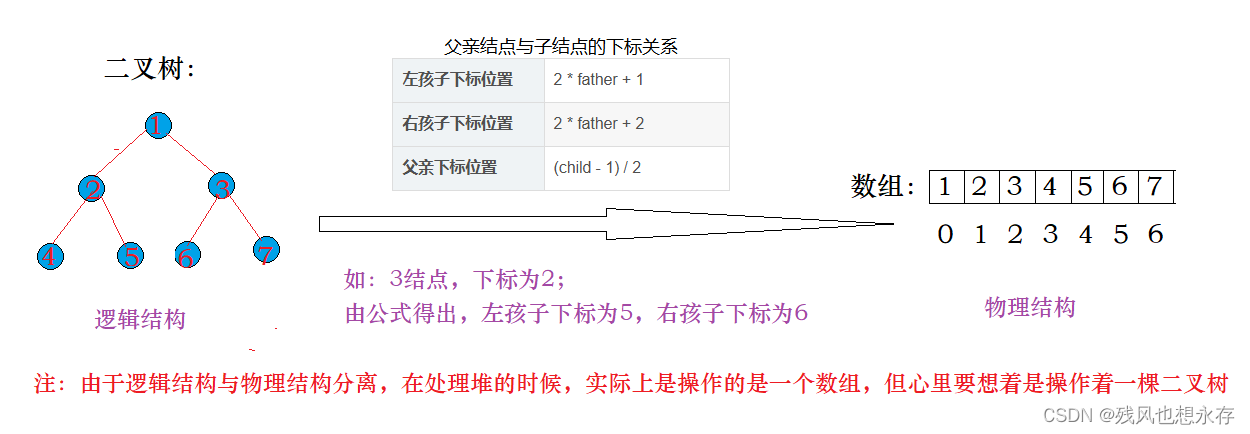
上期,我们讲过,对于完全二叉树,若用数组的下标0,1,2...,从左到右依次表示第一层,第二层...,则父亲结点与子结点的关系,可用下标表示出来。
而堆本身就是一种特殊的完全二叉树,所以用顺序结构表示堆,再简单不过~
二、堆的实现讲解
//堆的结构体声明与定义
typedef int HpDateType;
typedef struct Heap
{
HpDateType* date;
size_t size;
size_t capacity;
}Heap;
//堆的函数接口声明:
void HeapInit(Heap* php);//初始化
void HeapDestory(Heap* php);//销毁
void HeapPush(Heap* php, HpDateType x);//插入
void HeapPop(Heap* php);//删除堆顶的元素
HpDateType HeapTop(Heap* php);//返回堆顶元素
size_t HeapSize(Heap* php);//返回堆的数据个数
bool HeapEmpty(Heap* php);//判空//以下为上面函数接口的子函数,其目的是插入或
//删除元素后,符合堆的定义——但因其重要性~,下面会着重讲解
void AdjustUp(HpDateType* a, int n);//向上调整算法
void AdjustDown(HpDateType* a, int n, int size);向下调整算法
通过上面的声明,可以清楚的发现,其堆的实现,和动态顺序表的实现,极为相似;但又有一些区别; 比如在插入数据的时候,我们并不只是在最后一个数据的后面插入一个数据就行了,而是要通过向上调整算法,保持其符合堆的定义;在删除数据的时候,我们也不是删除最后一个数据,而是删除堆顶的元素。
1.向上调整算法
i.实现思路讲解
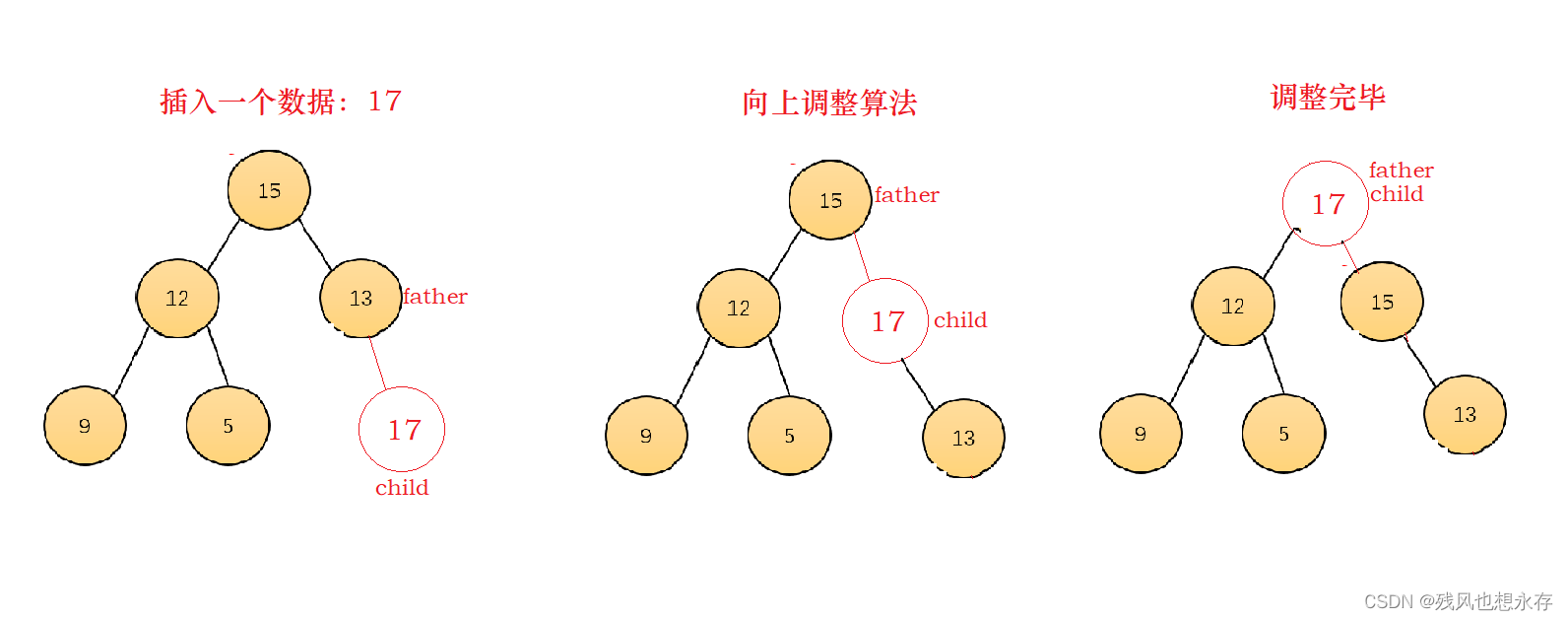
应用效果:给你一个堆,在尾部任意插入元素,将该结点调整到适合他的位置,大堆,比父亲小;若是小堆,比父亲小。
(建大堆)将插入得新结点,与其父亲做比较,若比父亲大,则交换数据,进行下一次循环,若比父亲小,或该结点的下标到0位置,则调整完毕,循环结束。
ii.复杂度
向上调整算法:最坏的情况,为调整高度次,假设二叉树的有N个结点,所以时间复杂度为O(logN)。

iii.代码
void AdjustUp(HpDateType* a, int n)
{
assert(a);
int child = n;
int father = (child - 1) / 2;
while (child > 0)
{
// 大堆
if (a[child] > a[father])
{
Swap(&a[father], &a[child]);
child = father;
father = (child - 1) / 2;
}
else
break;
}
}2.向下调整算法
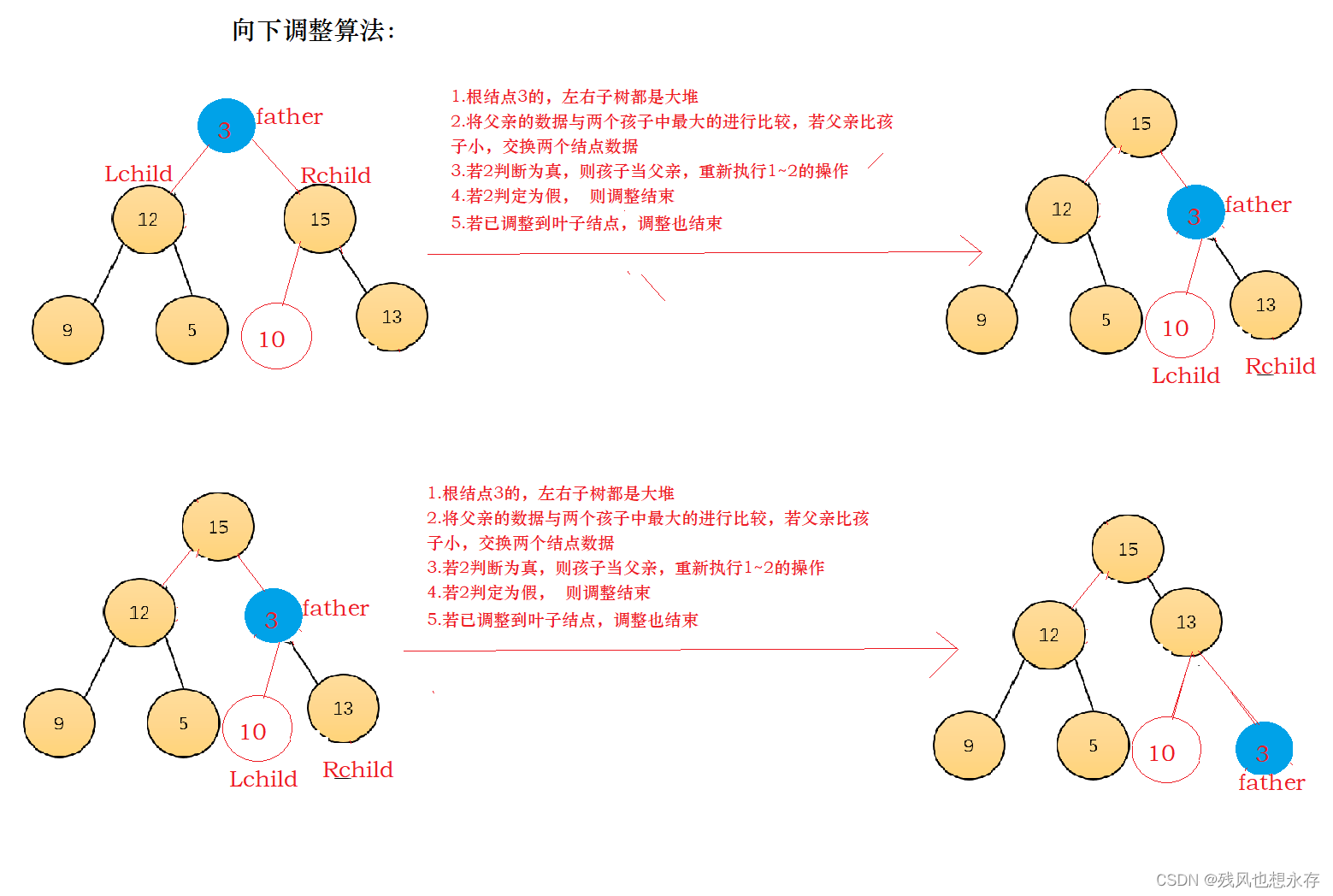
i.实现思路讲解
向下调整算法使用前提:左右子树是相同的堆,若是建小堆,左右子树都是小堆,才可使用向下调整算法;
ii.时间复杂度推导
向下调整算法:最坏的情况,为调整高度次,假设二叉树的有N个结点,所以时间复杂度为O(logN)。

iii.代码
void AdjustDown(HpDateType* a, int n, int size)
{
assert(a);
int father = n;
int child = 2 * father + 1;
while (2 * father + 1 < size)
{
// 左孩子比父亲大的假设不成立
if (child + 1 < size && a[child] < a[child + 1])
{
child += 1;
}
// 大堆
if (a[child] > a[father])
{
Swap(&a[child], &a[father]);
father = child;
child = 2 * father + 1;
}
else
break;
}
}3.插入元素
在插入数据的时候,我们并不只是在最后一个数据的后面插入一个数据就行了,而是要通过向上调整算法,保持其符合堆的定义;
void HeapPush(Heap* php, HpDateType x)
{
assert(php);
//查容 & 扩容
if (php->size == php->capacity)
{
size_t newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;
HpDateType* tmp = (HpDateType*)realloc(php->date, newcapacity * sizeof(HpDateType));
if (!tmp)
{
perror("realloc mistake");
exit(-1);
}
php->date = tmp;
php->capacity = newcapacity;
}
//插入
php->date[php->size++] = x;
//向上调整堆;
AdjustUp(php->date, php->size - 1);
}4.删除堆顶元素
在删除数据的时候,我们也不是删除最后一个数据,而是删除堆顶的元素。且要通过向下调整算法,保持其符合堆的定义;
void HeapPop(Heap* php)
{
assert(php);
assert(php->size > 0);
//踹走堆顶元素;
Swap(&php->date[0], &php->date[php->size-1]);
php->size--;
//向下调整堆
AdjustDown(php->date, 0, php->size);
}三、实现堆的源码
1.Heap.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<stdbool.h>
#include<time.h>
#include<assert.h>
typedef int HpDateType;
typedef struct Heap
{
HpDateType* date;
size_t size;
size_t capacity;
}Heap;
void HeapInit(Heap* php);//初始化
void HeapDestory(Heap* php);//销毁
void HeapPush(Heap* php, HpDateType x);//插入
void HeapPop(Heap* php);//删除
HpDateType HeapTop(Heap* php);//返回堆顶元素
size_t HeapSize(Heap* php);//返回堆的数据个数
bool HeapEmpty(Heap* php);//判空
void AdjustUp(HpDateType* a, int n);
void AdjustDown(HpDateType* a, int n, int size);2.Heap.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"
void HeapInit(Heap* php)
{
assert(php);
php->date = NULL;
php->size = php->capacity = 0;
}
void HeapDestory(Heap* php)
{
assert(php);
free(php->date);
php->date = NULL;
php->size = php->capacity = 0;
}
void Swap(HpDateType* e1, HpDateType* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
void AdjustUp(HpDateType* a, int n)
{
assert(a);
int child = n;
int father = (child - 1) / 2;
while (child > 0)
{
// 小堆
if (a[child] < a[father])
{
Swap(&a[father], &a[child]);
child = father;
father = (child - 1) / 2;
}
else
{
break;
}
}
}
void HeapPush(Heap* php, HpDateType x)
{
assert(php);
//查容 & 扩容
if (php->size == php->capacity)
{
size_t newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;
HpDateType* tmp = (HpDateType*)realloc(php->date, newcapacity * sizeof(HpDateType));
if (!tmp)
{
perror("realloc mistake");
exit(-1);
}
php->date = tmp;
php->capacity = newcapacity;
}
//插入
php->date[php->size++] = x;
//向上调整堆;
AdjustUp(php->date, php->size - 1);
}
void AdjustDown(HpDateType* a, int n, int size)
{
assert(a);
int father = n;
int child = 2 * father + 1;
while (2 * father + 1 < size)
{
// 左孩子比父亲小的假设不成立
if (child + 1 < size && a[child] > a[child + 1])
{
child += 1;
}
// 小堆
if (a[child] < a[father])
{
Swap(&a[child], &a[father]);
father = child;
child = 2 * father + 1;
}
else
{
break;
}
}
}
void HeapPop(Heap* php)
{
assert(php);
assert(php->size > 0);
//踹走堆顶元素;
Swap(&php->date[0], &php->date[php->size-1]);
php->size--;
//向下调整堆
AdjustDown(php->date, 0, php->size);
}
HpDateType HeapTop(Heap* php)
{
assert(php);
return php->date[0];
}
size_t HeapSize(Heap* php)
{
assert(php);
return php->size;
}
bool HeapEmpty(Heap* php)
{
assert(php);
return php->size == 0;
}四、堆的应用
1.建堆
i.向上调整建堆(时间复杂度推导)
问题:给你一个数组,返回一个大堆;
问起建堆,可能你们会说,创建一个堆的数据结构,然后不断的Push就行了;可是空间复杂度却是O(N),我们如何在空间复杂度O(1)的情况下,建一个堆呢?
HeapPush的时候,是在堆尾插入一个数据,然后向上调整,而我们其实可以省去插入的过程,在给定数组的上面,只使用向上调整算法,实现建堆;
省去了开辟空间的消耗,空间复杂度为O(1);时间复杂度为O(NlogN)


ii. 向下调整建堆(时间复杂度推导)
向上调整建堆的时间复杂度为O(NlogN),若面试官说O(NlogN),不好,问你能否将时间复杂度?你是否会觉得不可思议?而你又会如何解决呢?我们大脑的思维很难凭空创造,但我们可以从已有的问题,得到启发;下面我们重新分析一下向上调整建堆时间浪费在何处,
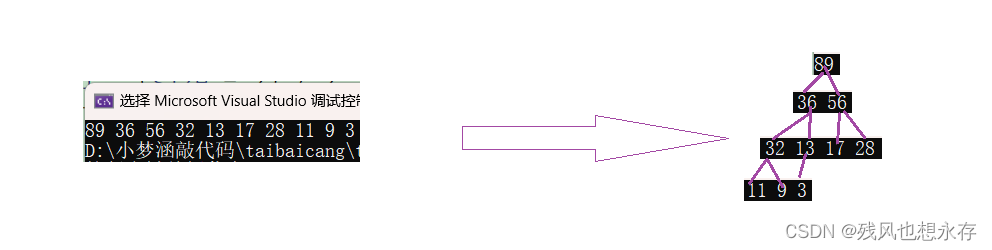
我们会发现,层数越高结点,最坏调整次数越高,与此同时,结点个数也越多,我说这可能是问题的突破高,我们如何让调整次数多的结点,个数减少呢?我们会想到向下调整算法,向下调整算法,有个使用前提:左右子树是相同的堆,才可使用向下调整算法。所以我们可以从最后一个非叶子结点往前调整;如上图,先向下调整28结点,依次往前13、56、32、...、到最后的根结点。
优点:结点个数越多的那一层,向下调整次数反而越少;时间复杂度为O(N)